Application servers 2004: A big muffin in a donut world
After my time at JRad, NetDynamics and Sun, I have been thinking about how application servers originated, what they were meant to do, and where they are going.
With the advent of the “Internet” age in 1995, all of a sudden corporate resources had to be available to HTML/HTTP clients. The HTML/HTTP clients were very different from previous clients in that they represented numerous intermittent connections, while in the previous client/server world there were generally a fixed number of clients with constant connections.
For example, an internal HR system that was built to support 30 HR reps and perhaps scale to 50 HR reps over the next couple of years was going to crawl if it all of a sudden had to handle 100,000 employees doing employee self-service during 401K election time, with each connection building and then tearing down a connection to the database.
Application servers were introduced to solve this problem. App servers would maintain a few open connections to the backend and queue the HTML/HTTP client requests into those connections. The back-end resources all used a variety of wacky protocols to access them, including things like dbClient, SQL*NET, CICS, SAP BAPI, PeopleSoft MessageAgent.
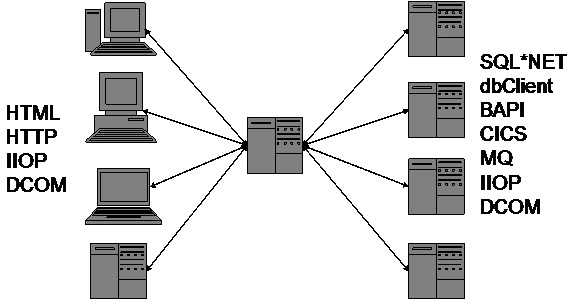
When enterprises took a deterministic, architectural perspective when implementing an application server, a requirement was to handle all of the wacky client protocols that were out there, like IIOP and DCOM, in addition to the variety of back-end protocols, so that the server could grow with you. The application server was nirvana for the CIO since it looked like it would solve the big corporate systems impedance mismatch as well as the pressing need to get these backend systems onto the web.
A bunch of these types of deployments were done in Java using servers like NetDynamics (acquired by Sun) and KIVA (acquired by Netscape). At this point, WebLogic only offered multi-tier JDBC drivers, had no clustering capabilities, and rudimentary application server features with their BeanT3 product.
After Java on the client started to stall, Sun noticed that customers were deploying Java on the server and began to create new API’s to standardize this space. Initially, these API’s were simple ones like JDBC and Servlets, but then evolved into JSP, EJB, JTA, JMS, and JCA and eventually fell under the umbrella brand J2EE. In the meantime, all clients became HTML/HTTP clients and no one was trying to build fat clients that used RMI, IIOP or DCOM.
So we entered the age of the standardized yet still very profitable application server, where everyone wanted to buy a server that would do everything when in actuality 80-90% of deployments were simply Servlet/JSP to JDBC applications.

In 1999, Sun acquired Netscape’s server line, including the original KIVA server. The KIVA server was primarily a C++ server and did not support the new Java standards well, but Sun chose it and killed the NetDynamics server it had bought a year earlier. BEA had acquired WebLogic in 1998, and in early 2000 WebLogic finally had enterprise features like clustering support and went on to dominate the J2EE market.
Yet there was a problem with the J2EE architecture: it is very hard to learn, use, and deploy. And whilst originally people though they would have “a” middle tier, they ended up with numerous middle tiers, running a variety of different versions of Java and .NET technologies, and these didn’t interoperate very well.
And so the industry started to shift towards interoperability, and as well all know from past experience, interoperability means MAKE IT DUMB. So after coalescing on self-describing text files (this is about as simple as it can get), the brave new world of web services was born.
Web services are creating an environment where all of the clients are text clients, either SOAP/HTTP or HTML/HTTP, and all of the back-ends serve text via SOAP/HTTP. This includes databases, ERP systems, CICS, MQ, basically everything.

The application server has become a big text pump, and the business logic has moved off to edge nodes. The databases, ERP systems, etc. themselves process the business logic and serve out self-describing text. The application server aggregates this text into something useful for the client.
Since the technology industry, like any industry, has the tendency to maintain the status quo, it is sometimes useful to step back and ask what type of solution would be created if the problems of today were suddenly foisted upon us.
So today’s problem is:
So what is the solution? We must remember that the original point of the application server was to solve the big corporate impedance mismatch and arbitrate connections to overwhelmed back-end resources. Today:
So perhaps the next generation Application Server is to have NO Application Server in the middle of everything. This is the “donut”, peer-to-peer architecture where there is nothing in the middle, versus the “muffin” architecture, where the Application Server sits in the middle of everything. Anything can talk to anything, and each node has its own mini application server built in so that it can talk to the rest of the world. The interoperability standard is web services, and each of these mini application servers can be written in anything - J2EE, .NET, LAMP, anything that can speak SOAP/HTTP.

Of course for the donut architecture to become fully realized, web services need to become transactional and offer guaranteed delivery. And yes, you can nest these servers, ie, have a portal server that calls a bunch of back-end web services. While theoretically you could call this a middle tier, it is not “the” middle tier, just another big text pump amongst many other text pumps.
So where is the application server of the future? It is a big text pump that is embedded in the various endpoints of an enterprise. There is nothing in the middle.